
19 Nov 2025
Survey data should be analysed with different tools at the same time in order to find the most appropriate method...
Survey data should be analysed with different tools at the same time in order to find the most appropriate method...

Internet of Things offers some easy and non-expensive ways to get started with Artificial Intelligence. Alexa is one of them....

Seit Jahren träumst du von einem persönlichen Assistenten wie Tony Starks Jarvis – und nun hast du Alexa. Sie schaltet...

Internet of Things offers some easy and non-expensive ways to get started with Artificial Intelligence. Alexa is one of them....

Jeremy was deputy department head at a medium size educational institution. We met Jeremy when we went through a series...

Robotic Process Automation (RPA) is one of the newer concepts for making our business and personal life easier. And this...

When I started dealing with data analytics, the focus was on learning the “sexy” statistics to help drawing business-relevant conclusions...

MySupplyChain is part of a logistics MNC and quite successful in all their business units. However, as data has shown:...

The digital revolution not only opens up new opportunities for how organisations arrange work and structure themselves, but it also...

Data analysts have not only the job to turn organisational data into information. They also need to master analytical storytelling....

Great, We Have Improved … or Not? About Sampling and Confidence Intervals Many companies spend considerable amounts of money on...
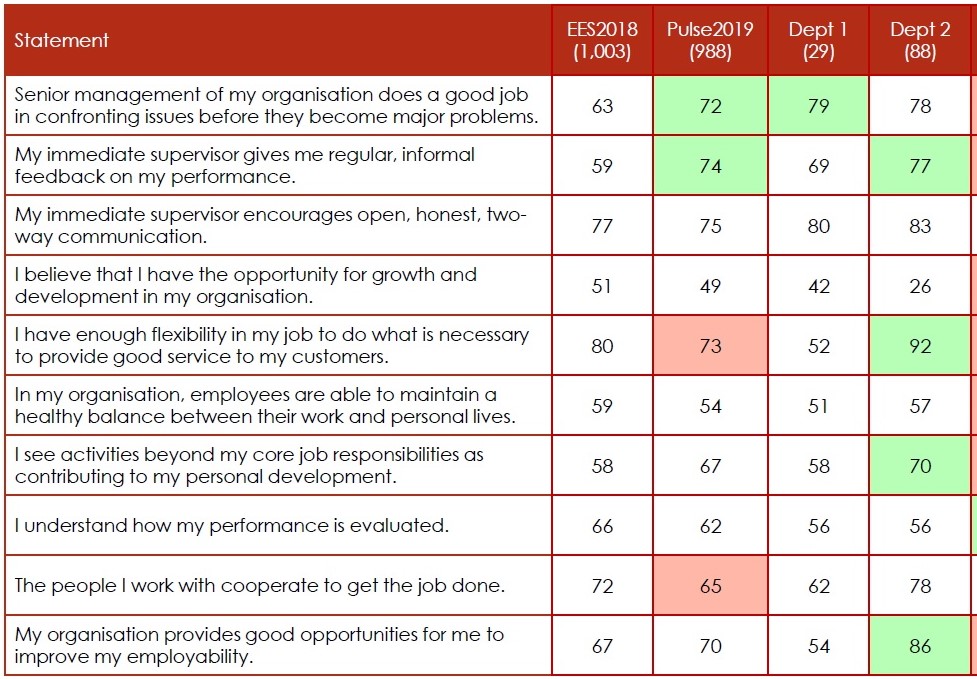
Many companies spend considerable amounts of money on customer and employee surveys every year. The survey results are used to...

At MyInsurance, survey results have been collected in 2017, 2018 and 2019. The rating was done on a 10-point Likert...

The Chi-Squared test is used to check whether there is a significant difference between observed frequencies (discrete data) and expected...
Survey data should be analysed with different tools at the same time in order to find the most appropriate method...

