Great, We Have Improved … Or Not?
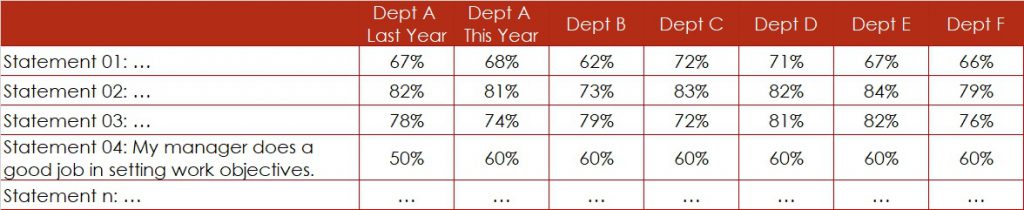
The management team is screening the survey results especially for statement “My manager does a good job in setting work objectives”, since this used to be an area of weakness last year (Figure 1). For Department A, they conclude that the satisfaction level – the percentage of favourable ratings – has gone up from 50% last year to 60% this year.
Great news, isn’t it?
We Got the Same Rating. That’s Great, Isn’t It?
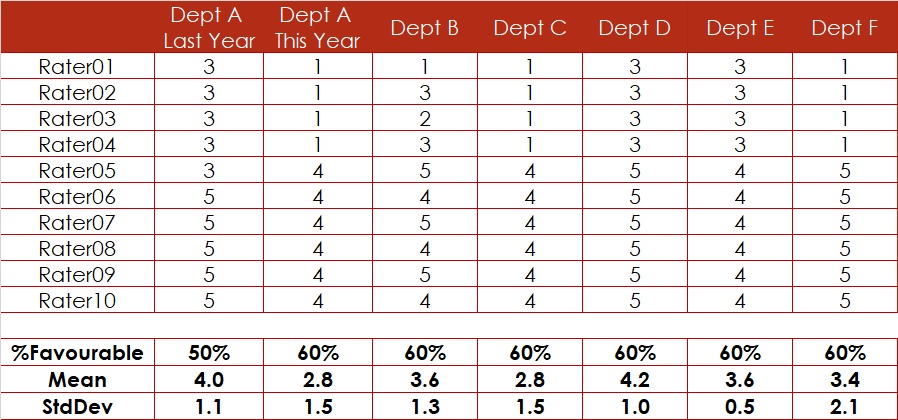
We Cannot Trust the Survey Results in %. What About the Means?
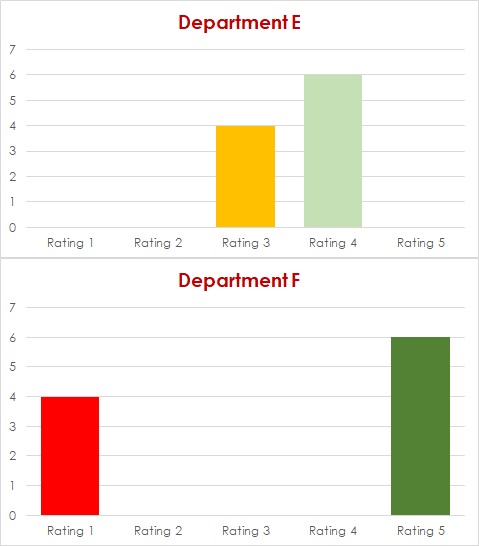
Are There Other Factors?
And, by poking into these details, you may find powerful levers for increasing staff satisfaction and engagement and, hence for boosting retention.
Conclusion
- Don’t look only at percentages. They can be lies.
- Looking at averages in addition to percentages improves the information content. To stay focussed and avoid getting lost in too many details, pay attention to significant differences only.
- Understanding the patterns in data would be best. However, it is not advisable and most likely not even possible for you to analyse the raw data. Therefore, develop a list of potential stratifying factors and have them applied to your data by your market researcher hoping that by doing so you discover all potential patterns in your data.
Epilogue
Congratulations to you if all the above considerations are old news to you. You do have a basic understanding of Data Analytics, the foundation of Data Science. With the ever-growing availablility of all kind of data in basically all sort of organisations, it is necessary to have at least a fundamental comprehension of the procedures for acquiring, cleaning, transforming, analysing, interpreting and visualising data.
- All Posts
- Data Science