20 Feb 2022
Lean Government. Even to the seasoned Lean practitioner, this idea sounds far-fetched. Governments are traditionally seen as the epitome of...
Lean Government. Even to the seasoned Lean practitioner, this idea sounds far-fetched. Governments are traditionally seen as the epitome of...

The Chi-Squared test is used to check whether there is a significant difference between observed frequencies (discrete data) and expected...

Consider a production process that produced 10,000 widgets in January and experienced a total of 112 rejected widgets after a...
Linear regression is one of the most commonly used hypothesis tests in Lean Six Sigma work. Linear regression offers the...
ANOVA (analysis of variances) is a statistical technique for determining the existence of differences among several population means. The technique...

In some situations, Six Sigma practitioners find a Y that is discrete and Xs that are continuous. How can a regression equation be...
More often than not, Lean Six Sigma practitioners have to find out whether two groups that look quite the same...

Measurement error is unavoidable. There will always be some measurement variation due to the measurement system itself. Most problematic measurement...
The DMAIC toolkit is excellent for solving technical complexity problems. However, Lean Six Sigma tools are not as adept at...
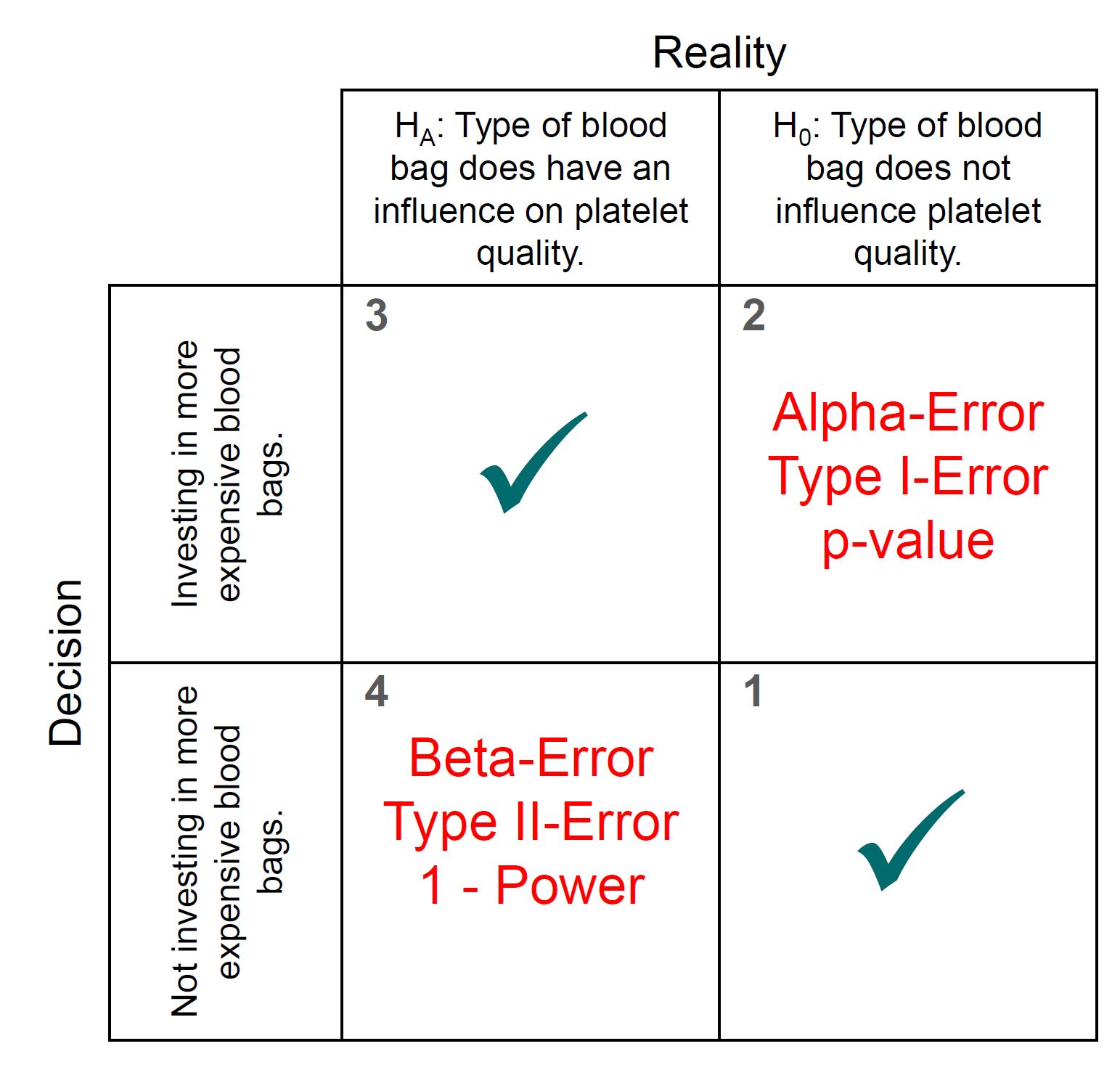
Rejecting a null hypothesis when it is false is what every good hypothesis test should do. The “power of the...