- Why is 58% customer satisfaction not better than 54%?
- Why is 58% customer satisfaction different to 58%?
To analyse the data, we follow the typical Data Analytics cycle. Since some of the functions needed are not available in Excel, we use the powerful programming language for statistics and visualisation R.
Business Question
- Firstly, is it significant?
- Secondly, is it large enough to have business impact?

Data Acquisition
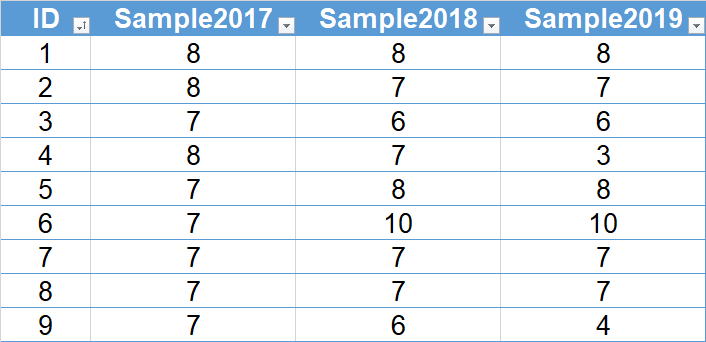
Get the data from Great.xlsx.
Data Preparation
Read More
# Loading necessary library
if(! “readxl” %in% installed.packages()) { install.packages(“readxl”, dependencies = TRUE) }
library(readxl)
# Read Data from Excel Table into R dataframe Great
Great <- read_excel(“Great.xlsx”, sheet = “Great”, range = “A1:D281”)
# Load necessary library
if(! “utils” %in% installed.packages()) { install.packages(“utils”, dependencies = TRUE) }
library(utils)
# Stack data in GreatStacked and ignore column ID
GreatStacked <- stack(Great, select = -ID)
# Create additional columns Satisfied/Non-Satisfied and counter
GreatStacked$sat <- ifelse(GreatStacked$values > 7, “Satisfied”, “Non-Satisfied”)
GreatStacked$num <- 1
Data Analysis
Calculating Satisfaction Score Per Year
Read More
# Calculate the percentages
library(dplyr)
library(plyr)
library(tidyr)
df <- GreatStacked %>% group_by(ind, sat, .drop=FALSE) %>% tally#
Prepare percentages and labels, data aggregation
df = ddply(df, .(ind), transform, percent = n/sum(n) * 100)
df = ddply(df, .(ind), transform, pos = (cumsum(n) – 0.5 * n))
df$label = paste0(sprintf(“%.0f”, df$percent), “%”)
# Plotting bar chart and turning it 90 degree
library(ggplot2)
ggplot(df, aes(x = factor(ind), y = n, fill = sat)) +
geom_bar(position = position_stack(), stat = “identity”, width = .7) +
geom_text(aes(label = label), position = position_stack(vjust = 0.5), size = 5) +
ggtitle(“Customer Satisfaction per Year”) + labs(fill = “”) +
theme(plot.title = element_text(color = “maroon”, size = 20, face=”bold”),
text = element_text(color = “black”, size = 18, angle = 0, hjust = 1, vjust = 0)) +
xlab(“”) + ylab(“”) + ylim(0, 300) + coord_flip()
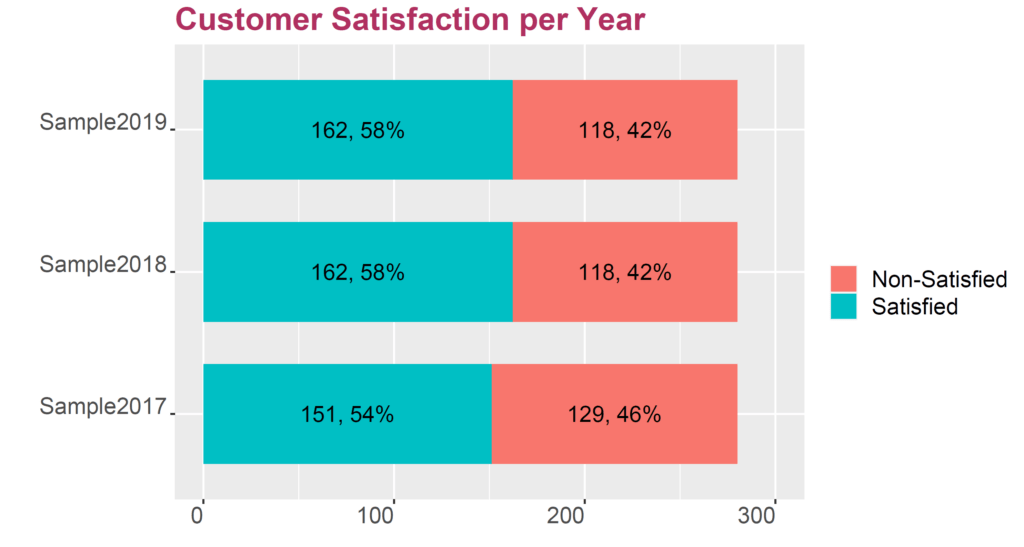
Determining Significance of Improvement
Read More
# Compare proportions of Sample2017 with Sample2018/Sample2019
prop.test(x = c(151, 162), n = c(280, 280), p = NULL, alternative = “two.sided”, correct = TRUE)
Result: X-squared = 0.72435, df = 1, p-value = 0.3947 alternative hypothesis: two.sided 95 percent confidence interval: -0.12503912 ... 0.04646769 sample estimates: prop 1 prop 2 0.5392857 0.5785714
Analysing Raw Data
There are many different tests for normality, that determine whether a set of data is similarly distributed as the bell shape described by Gauss in 1809. The Shapiro-Wilk normality test is a preferred one.
Read More
# Perform Shapiro-Wilk normality test on all data in GreatStacked column values by ind
with(GreatStacked, tapply(values, ind, shapiro.test))
Result:
$Sample2017
Shapiro-Wilk normality test
W = 0.76188, p-value = 0.0000
$Sample2018
Shapiro-Wilk normality test
W = 0.90083, p-value = 0.0000
$Sample2019
Shapiro-Wilk normality test
W = 0.83921, p-value = 0.0000
Read More
# Perform Wilcoxon-test on GreatStacked values by ind
library(rstatix)
wilcox_test(GreatStacked, values ~ ind)
Result y group1 group2 n1 n2 p.adj values Sample2017 Sample2018 280 280 0.202 values Sample2017 Sample2019 280 280 0.589 values Sample2018 Sample2019 280 280 0.026
Surprise 1
Surprise 2
Plotting the Data
An essential step in any data analytics is the graphical display of data. This does not mean, one graph will suffice. It means the data analyst needs to perform multiple plots in oder to reveal the truth lurking in the data.
Read More
# Tally data for each year
df2017 <- Great %>% group_by(Sample2017, .drop=FALSE) %>% tally
df2018 <- Great %>% group_by(Sample2018, .drop=FALSE) %>% tally
df2019 <- Great %>% group_by(Sample2019, .drop=FALSE) %>% tally
# Prepare multi-pane plot
library(graphics)
par(mfrow = c(1, 3), mar = c(2, 5, 3, 3), oma = c(2, 2, 2, 2))
# Plot series of graphs for rating distribution
barplot(height = df2017$n, names = df2017$Sample2017, xlab = “Rating”, xlim = c(0, 10), ylim = c(0, 130), ylab = “Number of Ratings”, main = “Rating in 2017”, col = c(“pink”, “pink”, “pink”, “pink”, “pink”, “pink”, “pink”, “lightgreen”, “lightgreen”, “lightgreen”))
barplot(height = df2018$n, names = df2018$Sample2018, xlab = “Rating”, xlim = c(0, 10), ylim = c(0, 130), ylab = “Number of Ratings”, main = “Rating in 2018”, col = c(“pink”, “pink”, “pink”, “pink”, “pink”, “pink”, “pink”, “lightgreen”, “lightgreen”, “lightgreen”))
barplot(height = df2019$n, names = df2019$Sample2019, xlab = “Rating”, xlim = c(0, 10), ylim = c(0, 130), ylab = “Number of Ratings”, main = “Rating in 2019”, col = c(“pink”, “pink”, “pink”, “pink”, “pink”, “pink”, “pink”, “lightgreen”, “lightgreen”, “lightgreen”))
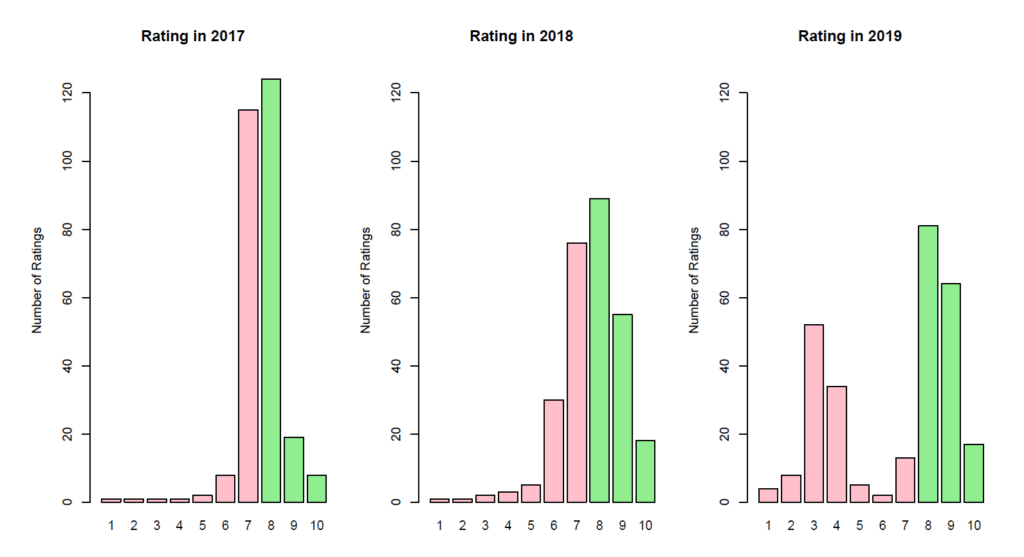
Business Decision
- There is no evidence that the customer satisfaction has increased from 2017 to 2018 or 2019. Any reward for successful work would come with a risk of being wrong of about 39.5%. Any celebration would be premature.
- There has been a significant change from 2018 to 2019. In 2018, a homogenious rating pattern could be observed. In 2019, two clusters are obvious. There must be further investigation to identify the root causes for that change and especially for the clusters.
- Survey data analysis should not rely on percentages only. Either your data analyst or your market research partner must perform in-depth analyses.
- Never forget to plot the data.

Data Analytics for Organisational Development
If you wish to explore more cases of supporting organisational development with data analytics using MS Excel, MS PowerBI and R, if you wish to download the raw data for this and many other cases and if you wish to follow through the analysis step by step, these books might be of interest for you.


- All Posts
- Data Science