19 Nov 2025
Survey data should be analysed with different tools at the same time in order to find the most appropriate method...
Survey data should be analysed with different tools at the same time in order to find the most appropriate method...

Jeremy was deputy department head at a medium size educational institution. We met Jeremy when we went through a series...

Lean Six Sigma (LSS) has proven to be a methodology that can add measurable benefits to organisations, However, it has...

Robotic Process Automation (RPA) is one of the newer concepts for making our business and personal life easier. And this...

Lean Government. Even to the seasoned Lean practitioner, this idea sounds far-fetched. Governments are traditionally seen as the epitome of...

Do You Like Spaghetti? About unnecessary motion and other lean sins “I did a lot of spaghetti walk this morning”,...

“Voice of the Customer” – VOC in short – is a key topic in all kind of customer service, TQM...
The Moment of Truth is the short time frame when a customer experiences the product or service that many people...

Great, We Have Improved … or Not? About Sampling and Confidence Intervals Many companies spend considerable amounts of money on...
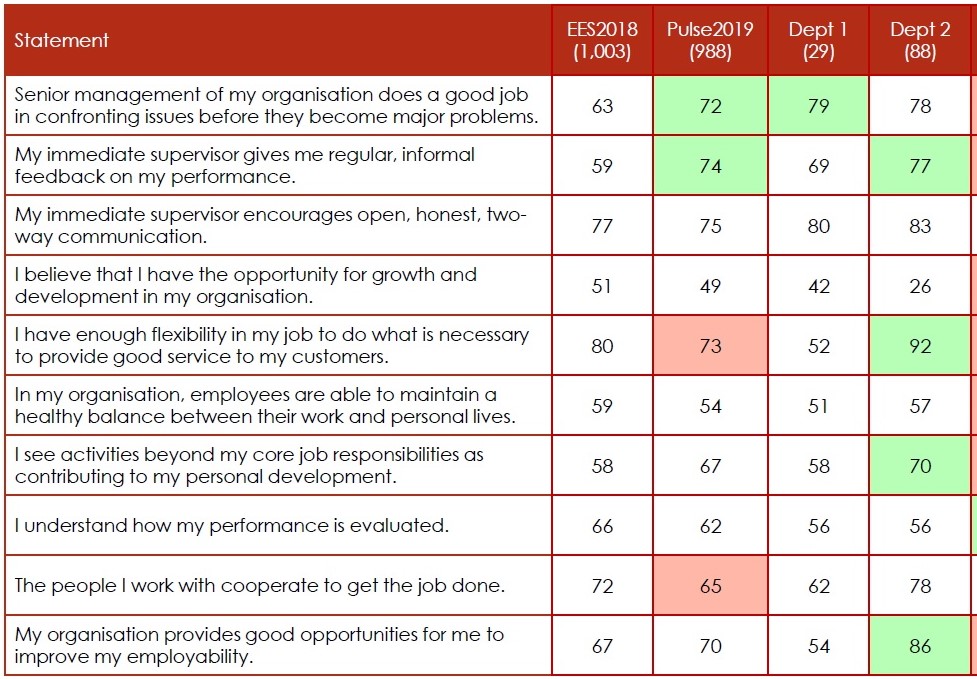
Many companies spend considerable amounts of money on customer and employee surveys every year. The survey results are used to...

At MyInsurance, survey results have been collected in 2017, 2018 and 2019. The rating was done on a 10-point Likert...

MYTH: LEAN SIX SIGMA HAS MANY TOOLS I DO NOT NEED. Certainly, life is much easier without the need to...
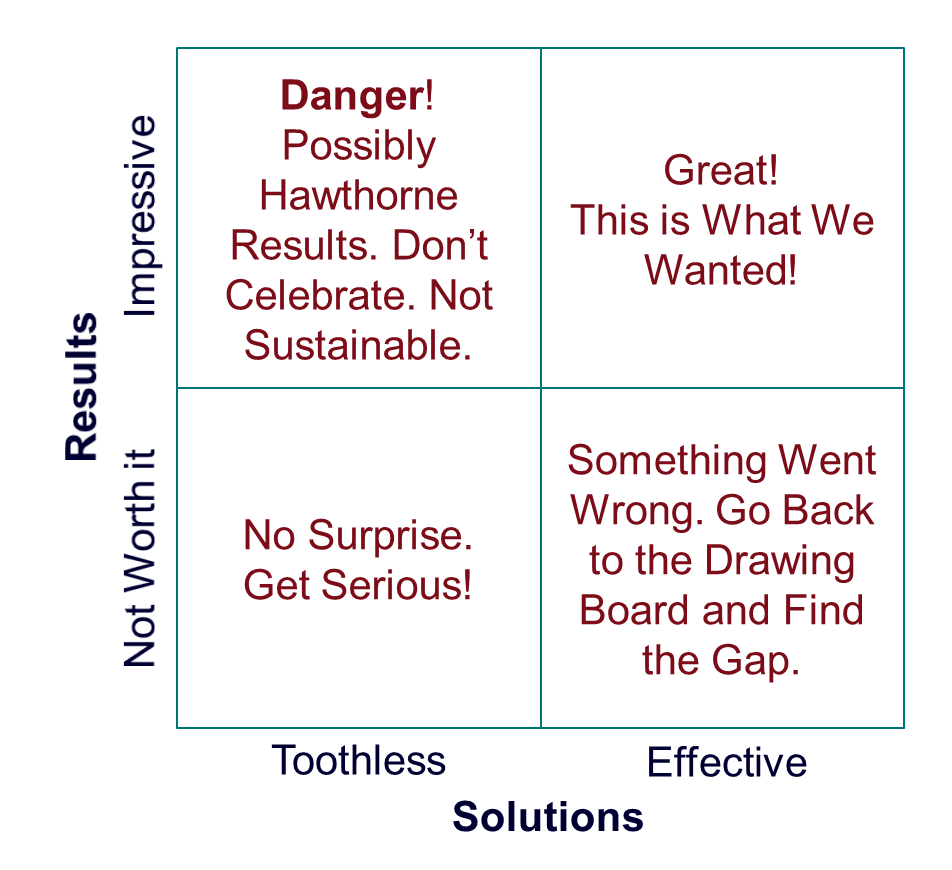
“We have great news for you. Our project is delivering results already.” The team is all smiles when they give...

Just some weeks ago, I filed my tax in Singapore. It took me about twelve minutes at my computer at...

The Chi-Squared test is used to check whether there is a significant difference between observed frequencies (discrete data) and expected...