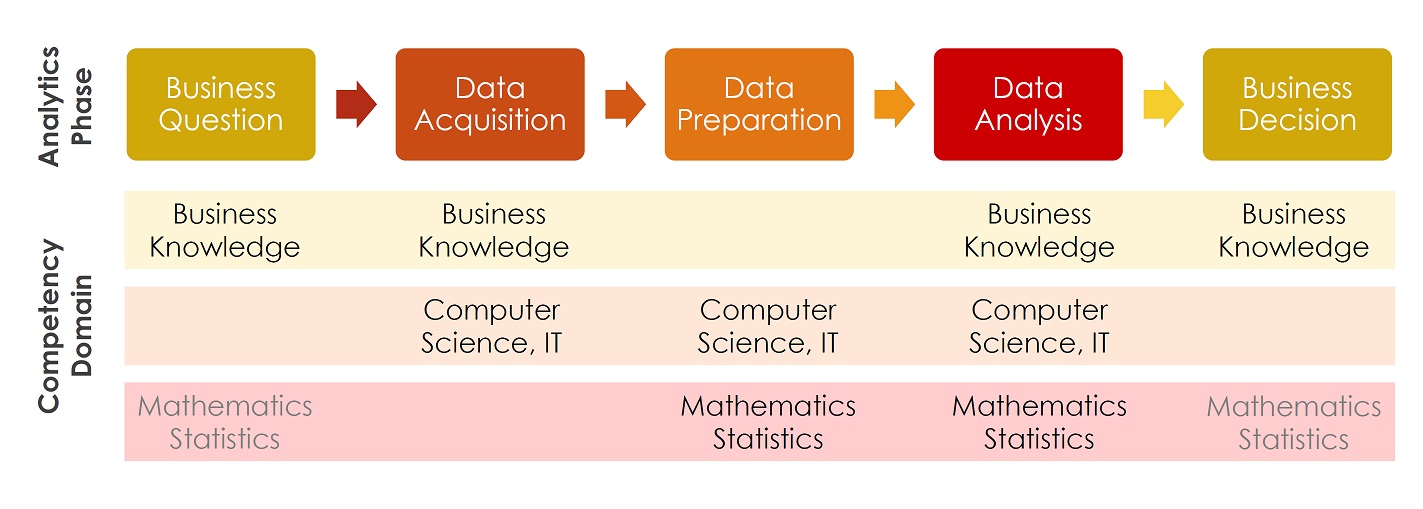
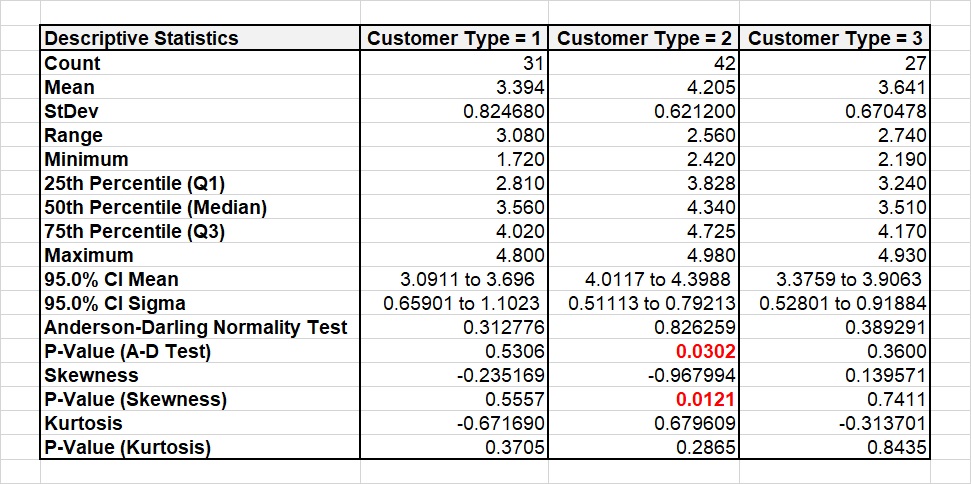
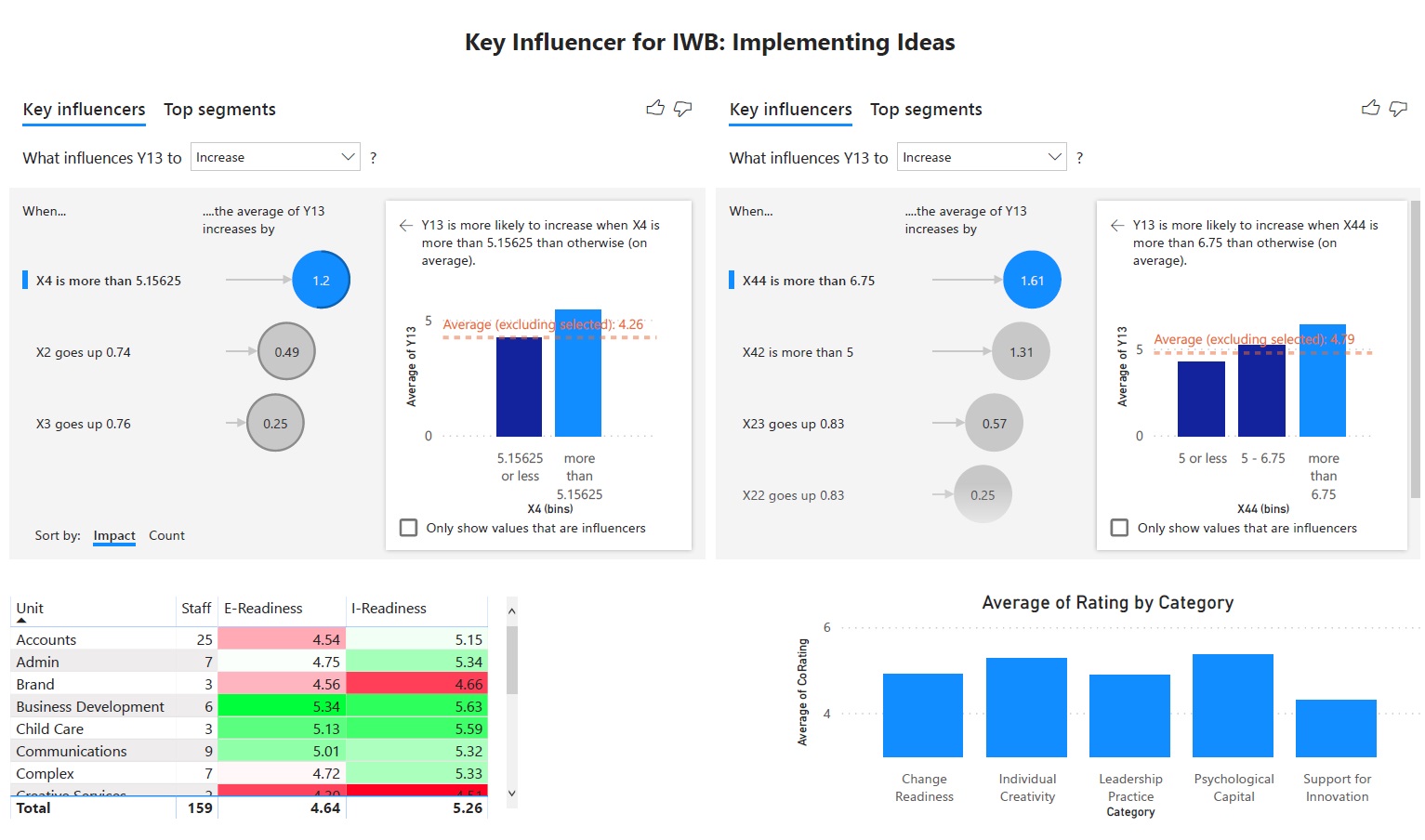
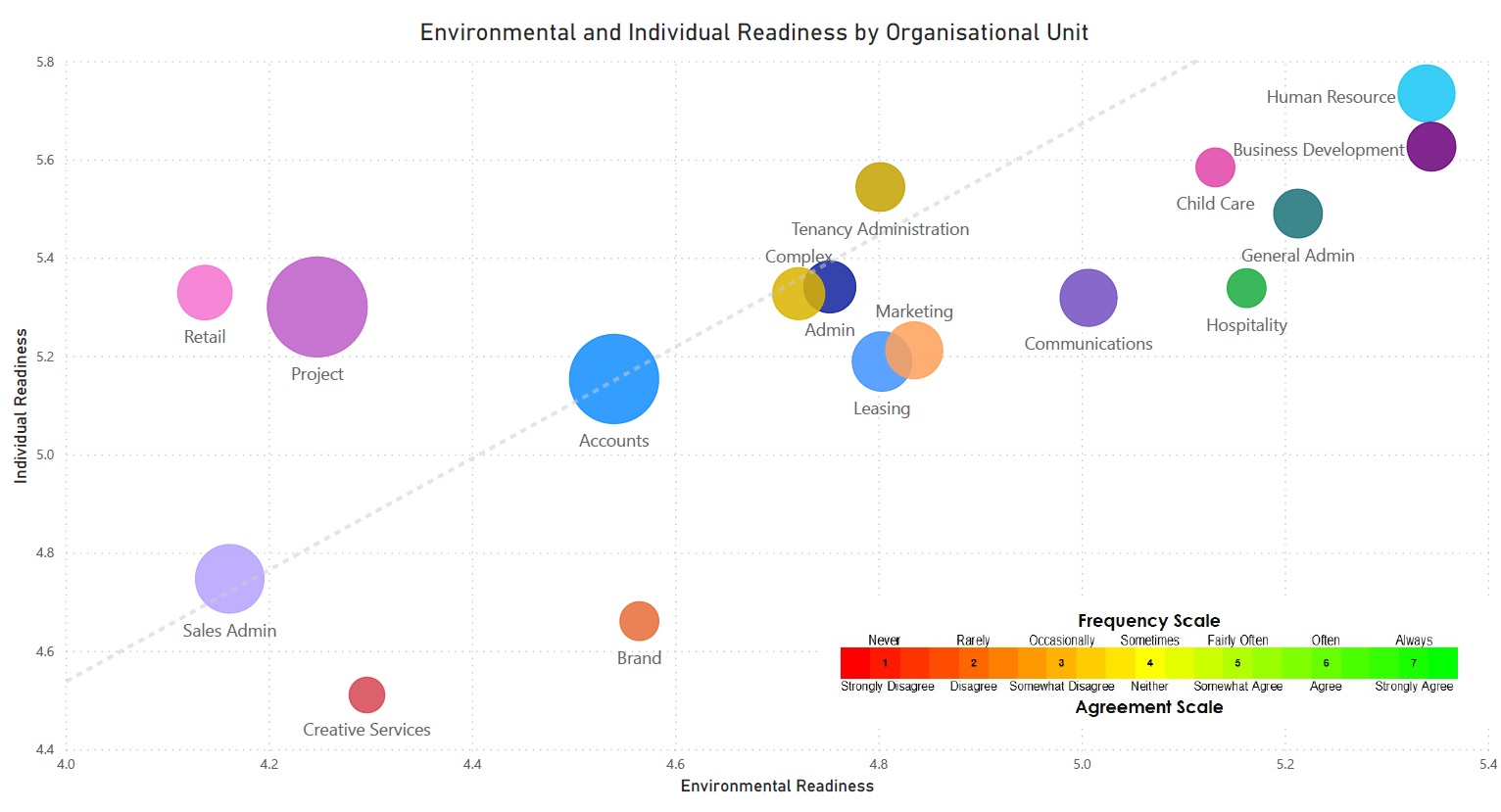
Data analytics can be helpful in problem solving by establishing the significance of the relationship between problems (Y) and potential root causes (X). As a result, a large variety of tools is available.
The selection of tools for a given data analytics task depends on the overall objective, the source and types of data. Discrete data, such as counts or attributes require different tools than continuous data, such as measurements. Whilst continuous data are transformable into discrete data for decision making, this process is irreversible.