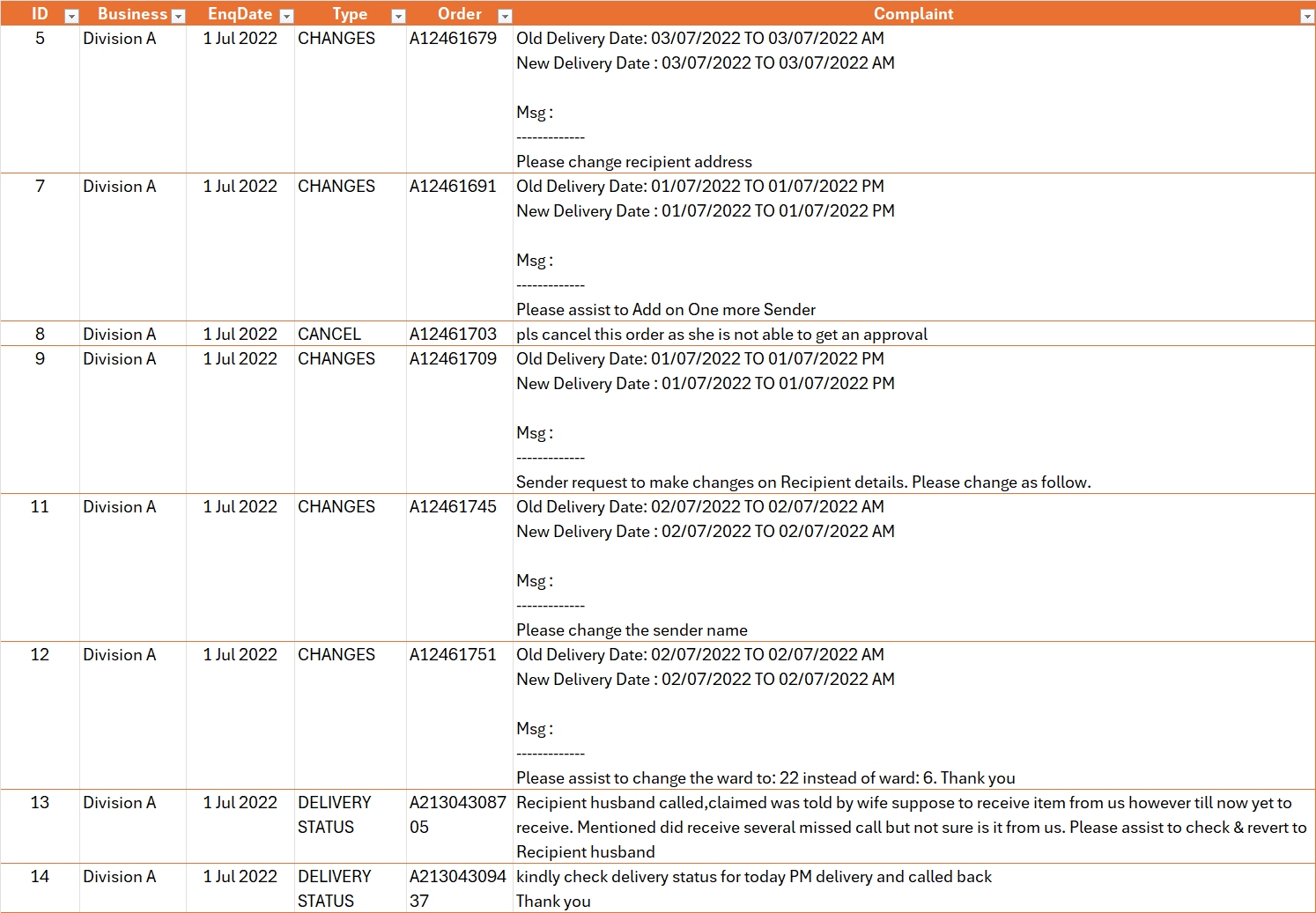
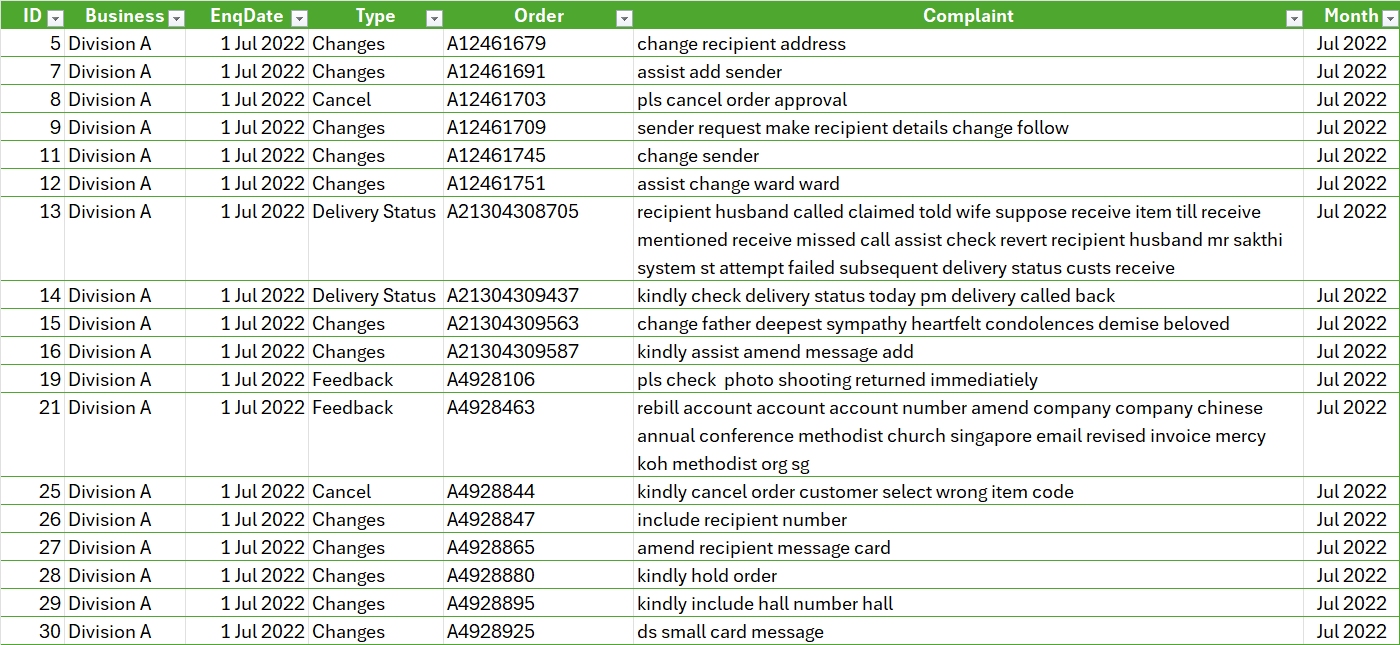
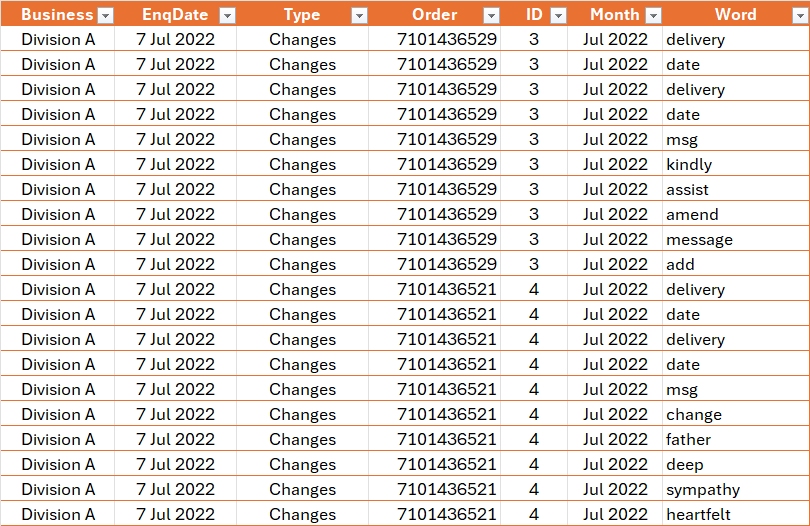
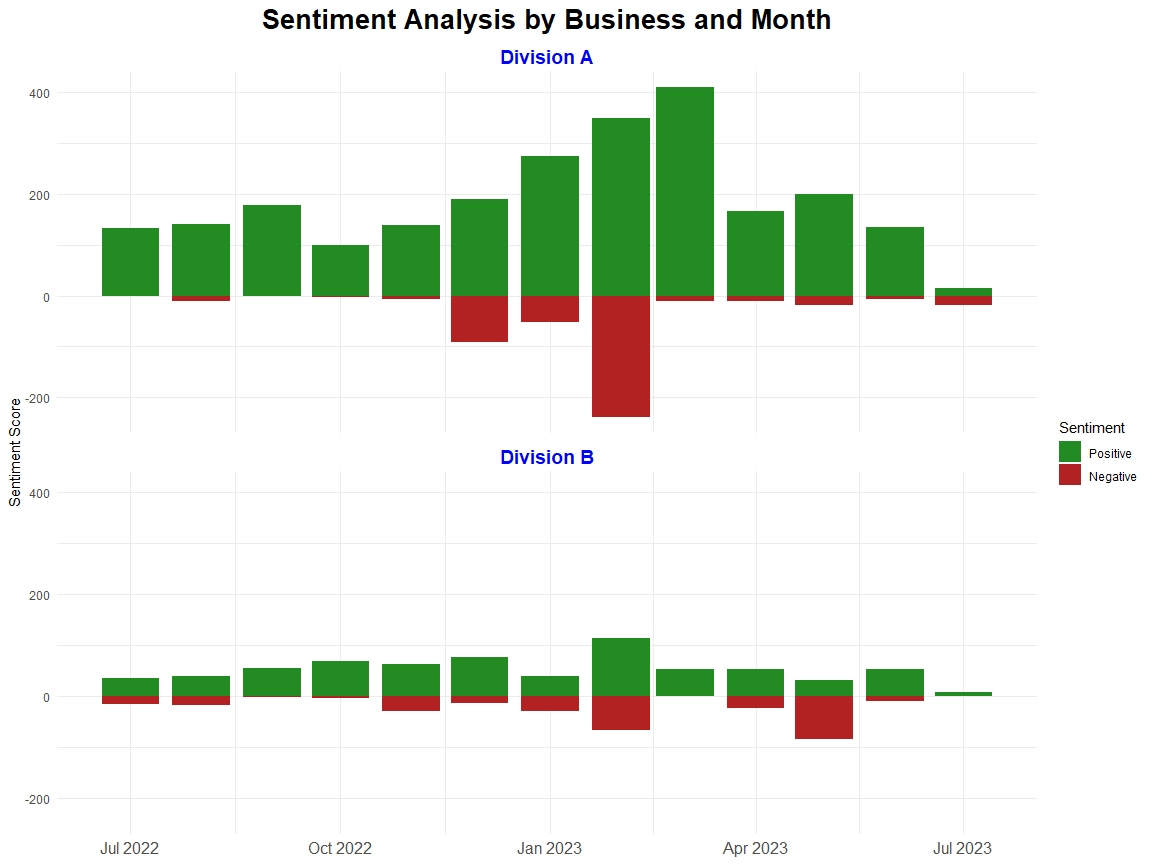
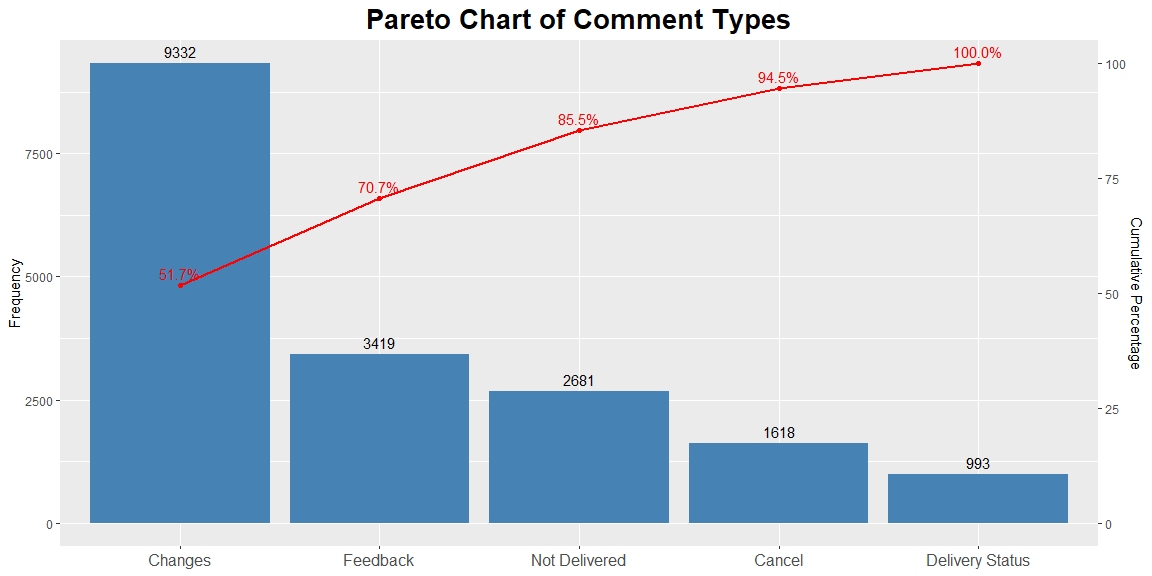
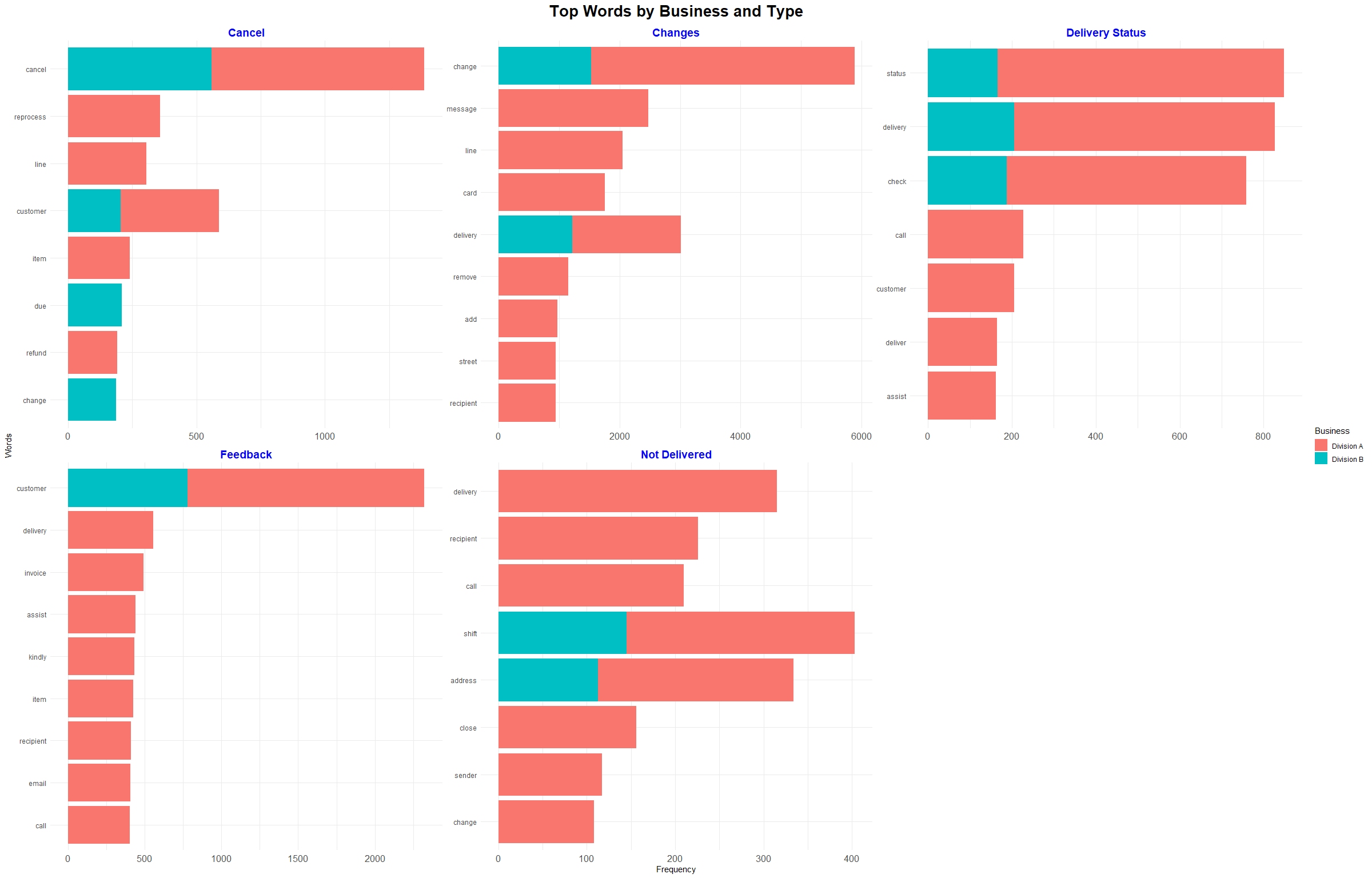
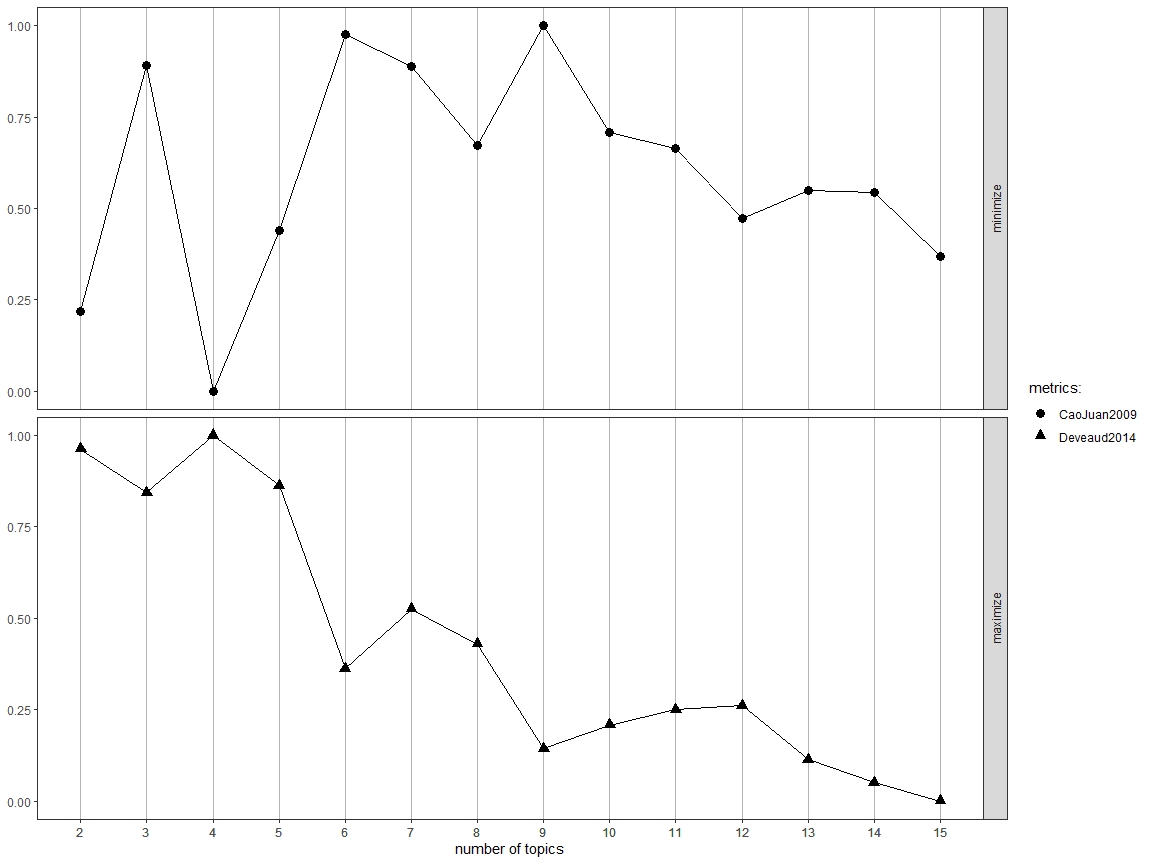
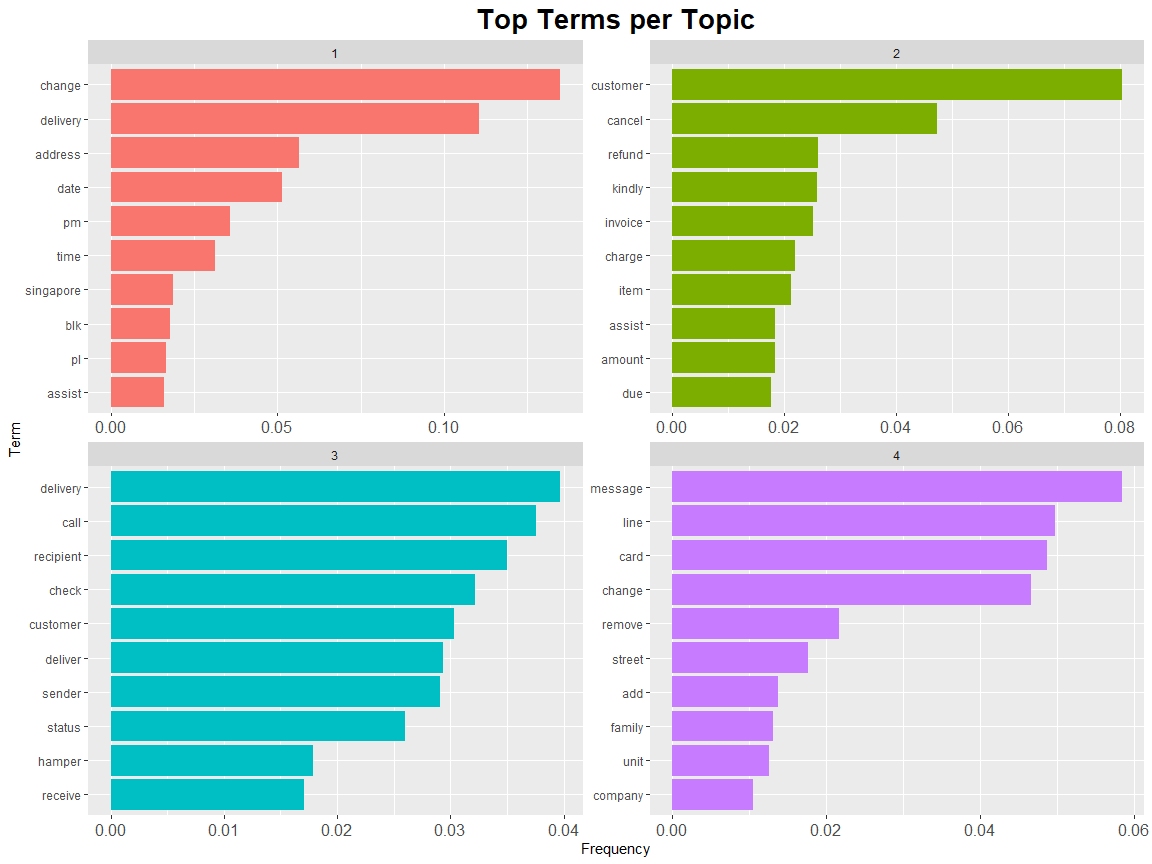
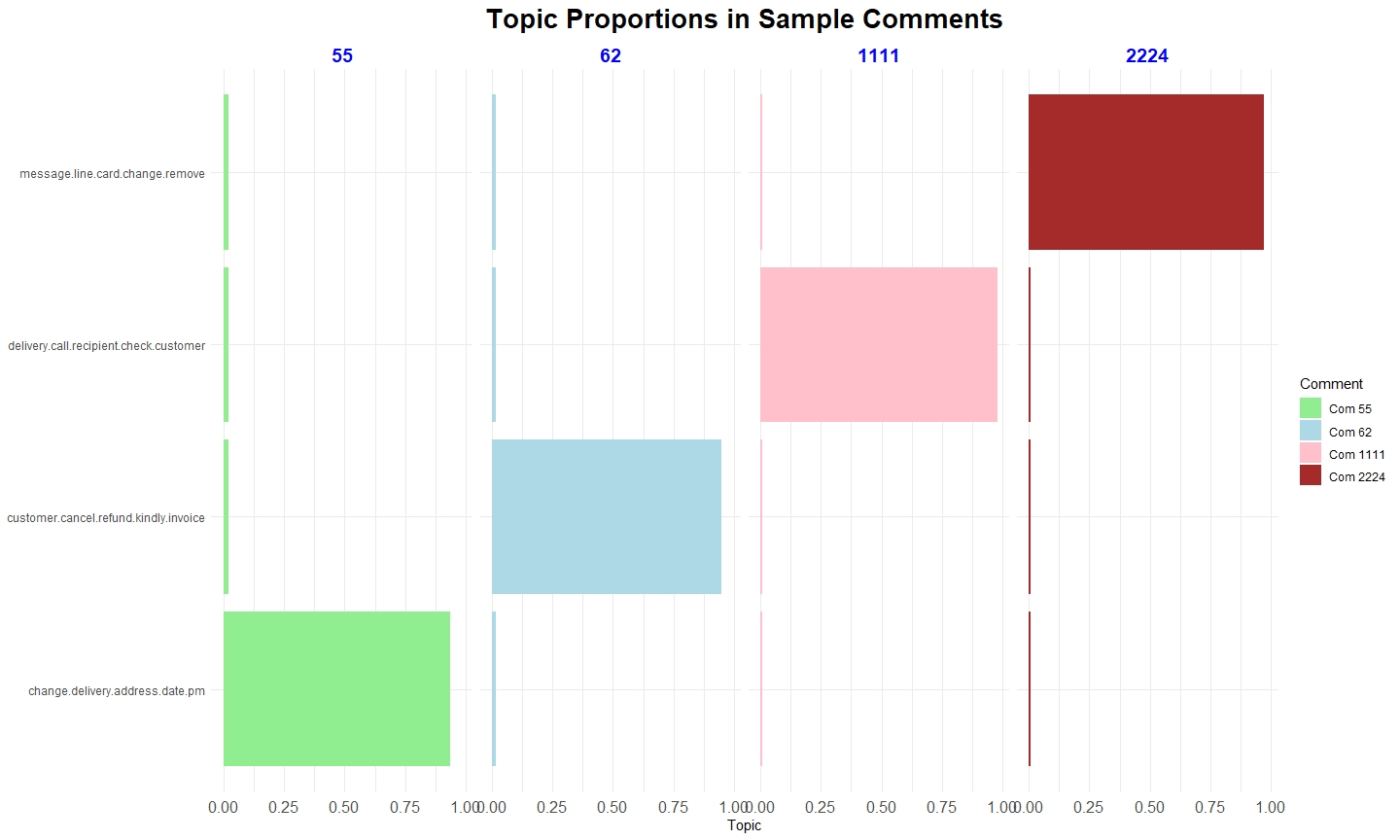
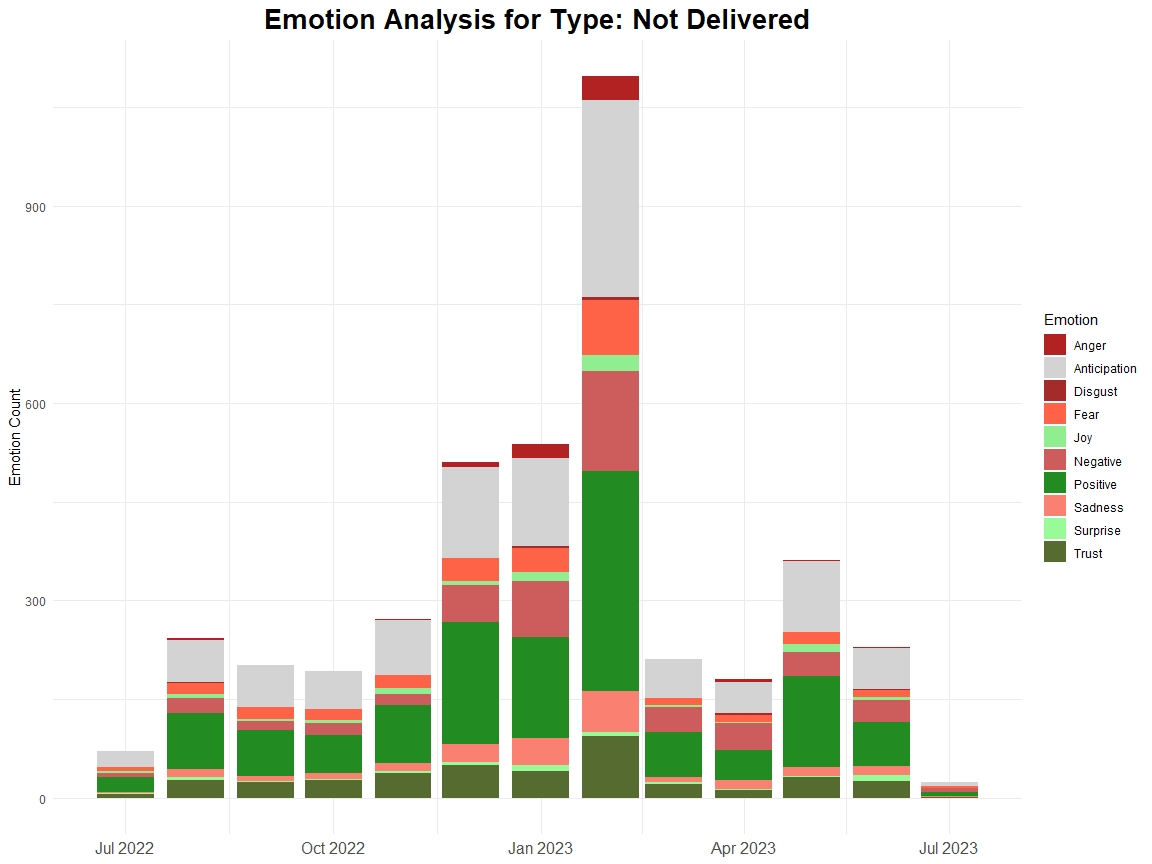
Text mining, also known as text analytics, is the process of extracting meaningful insights and patterns from unstructured textual data. By applying techniques such as natural language processing (NLP), sentiment analysis, and topic modelling, text mining transforms raw text into structured data for analysis.
It is widely used in applications like customer feedback analysis, spam detection, social media monitoring, and document classification. This powerful approach helps uncover hidden trends, relationships, and actionable insights, enabling businesses and researchers to make data-driven decisions.
This case shows a comprehensive example of Text Analytics with R.