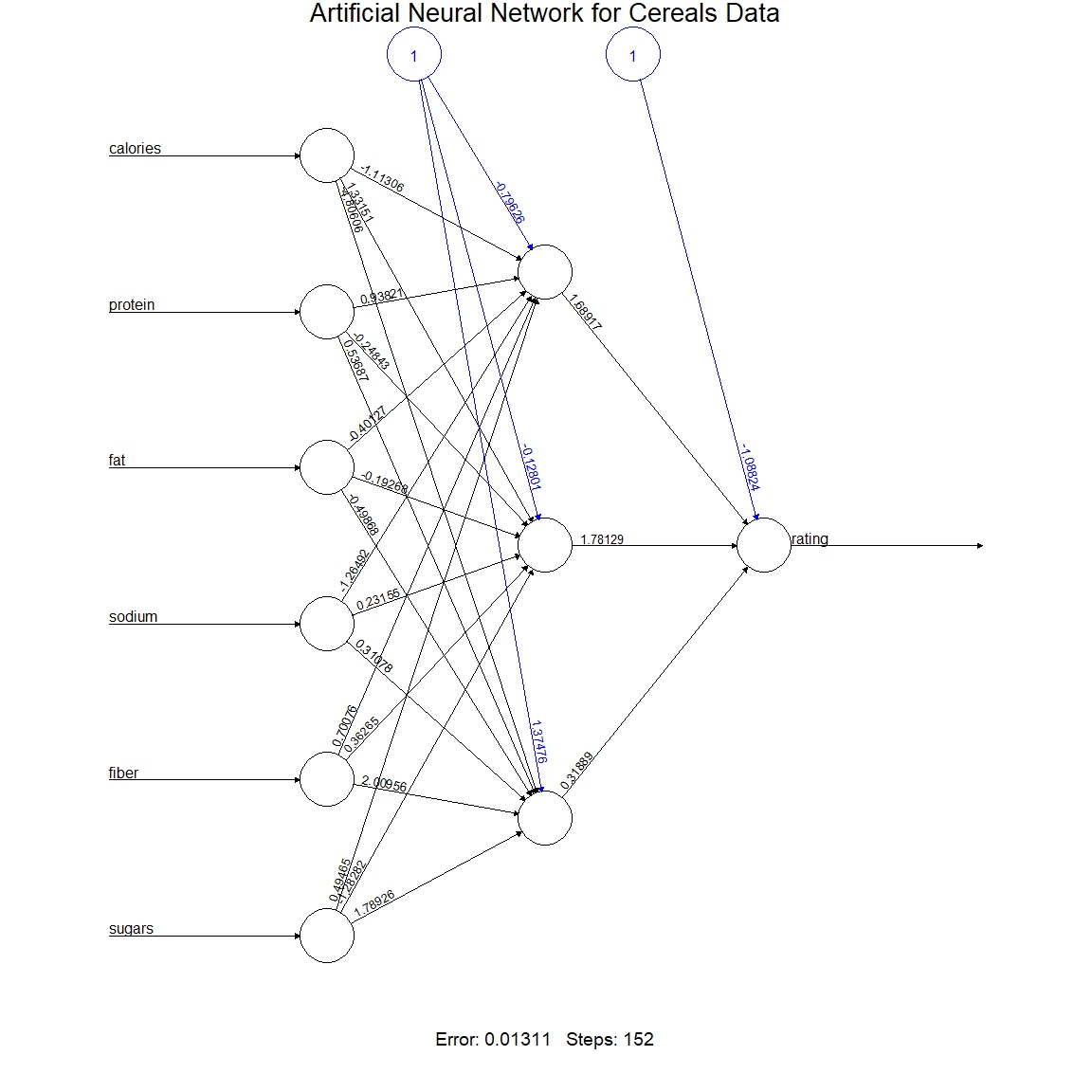
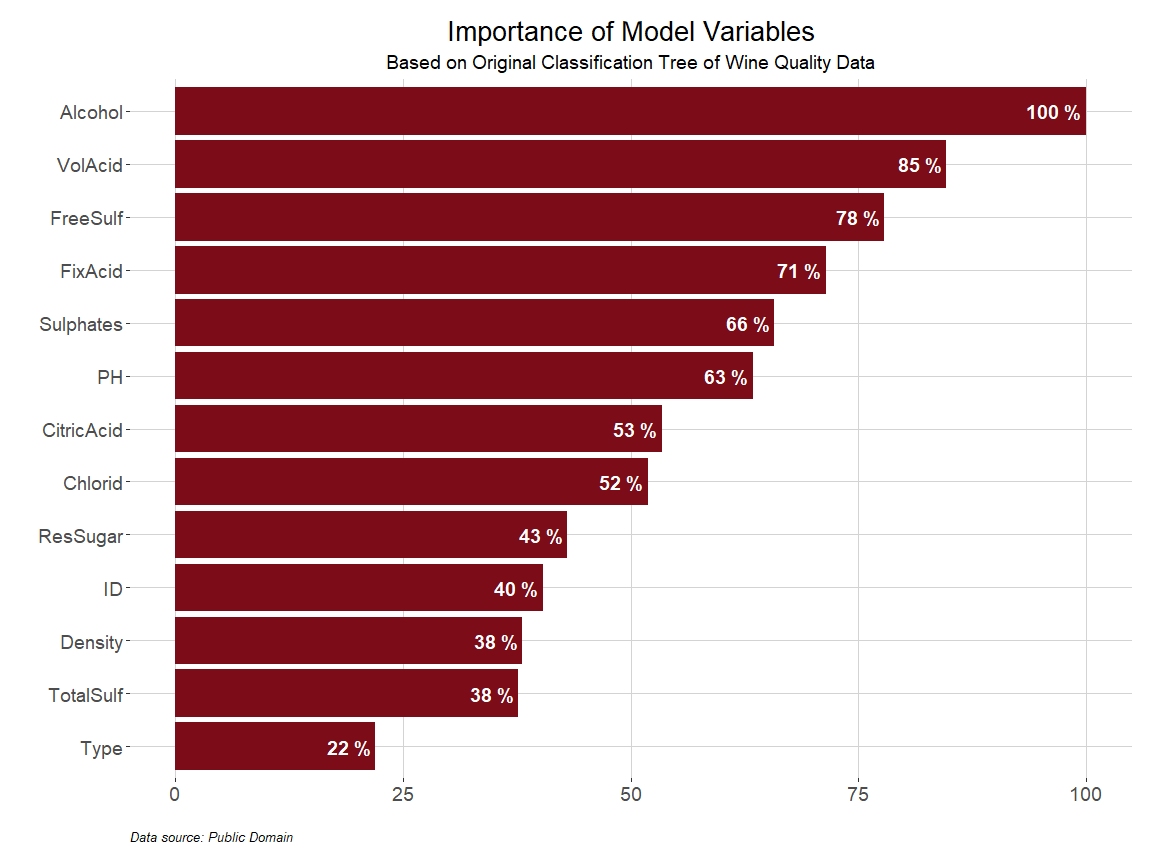
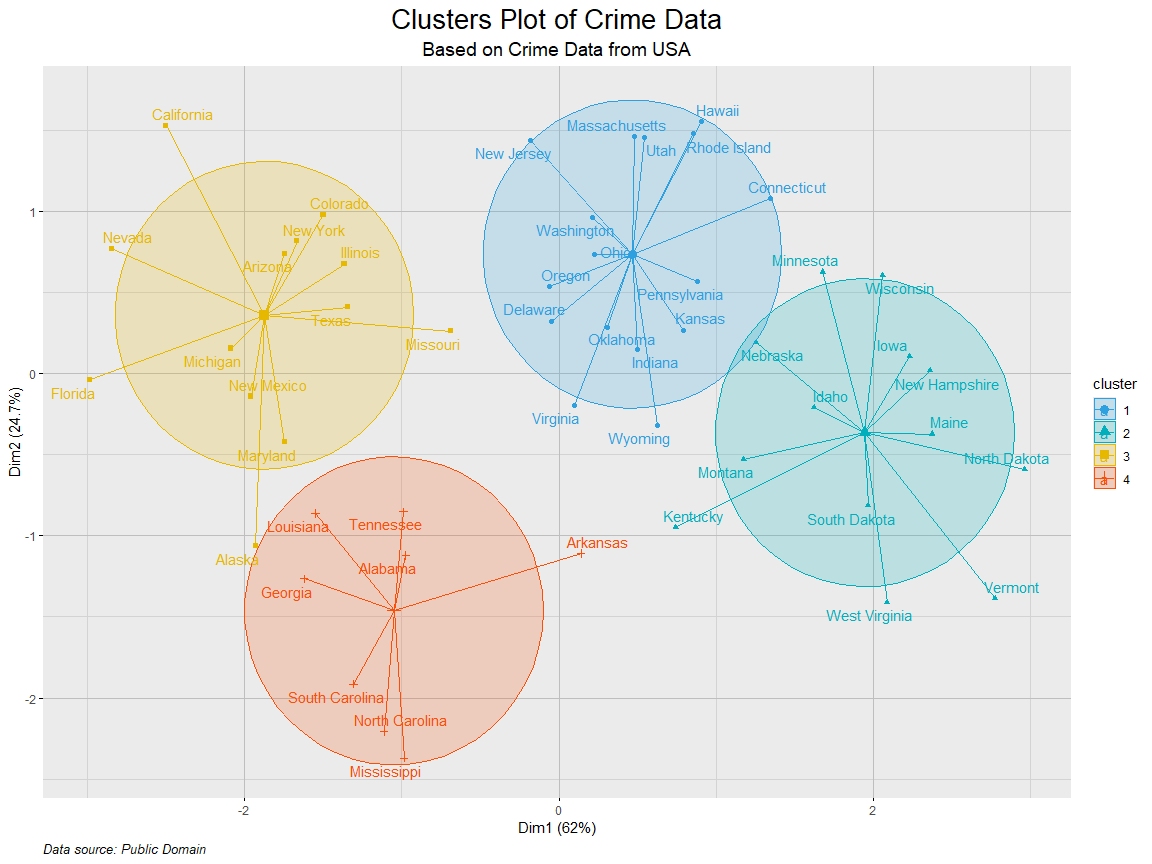
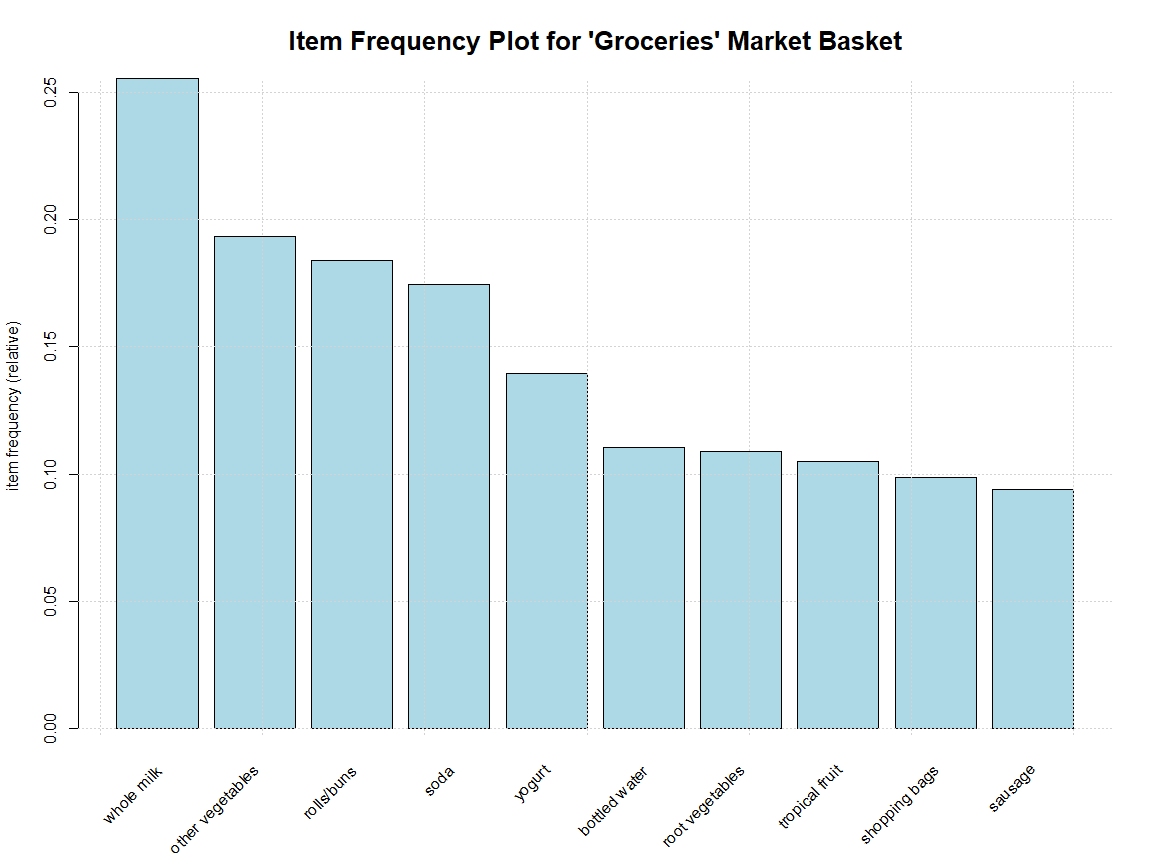
Association rule mining is a data mining technique used to uncover relationships between variables in large datasets.
It is commonly applied in market basket analysis to identify product purchase patterns, such as “customers who buy bread often buy butter.”
The most well-known algorithm for generating association rules is the Apriori algorithm, which uses support, confidence, and lift measures to determine rule significance.
This technique helps businesses optimise marketing strategies, improve recommendations, and enhance inventory management.
By discovering meaningful associations, organisations can gain valuable insights into consumer behaviour and data dependencies.