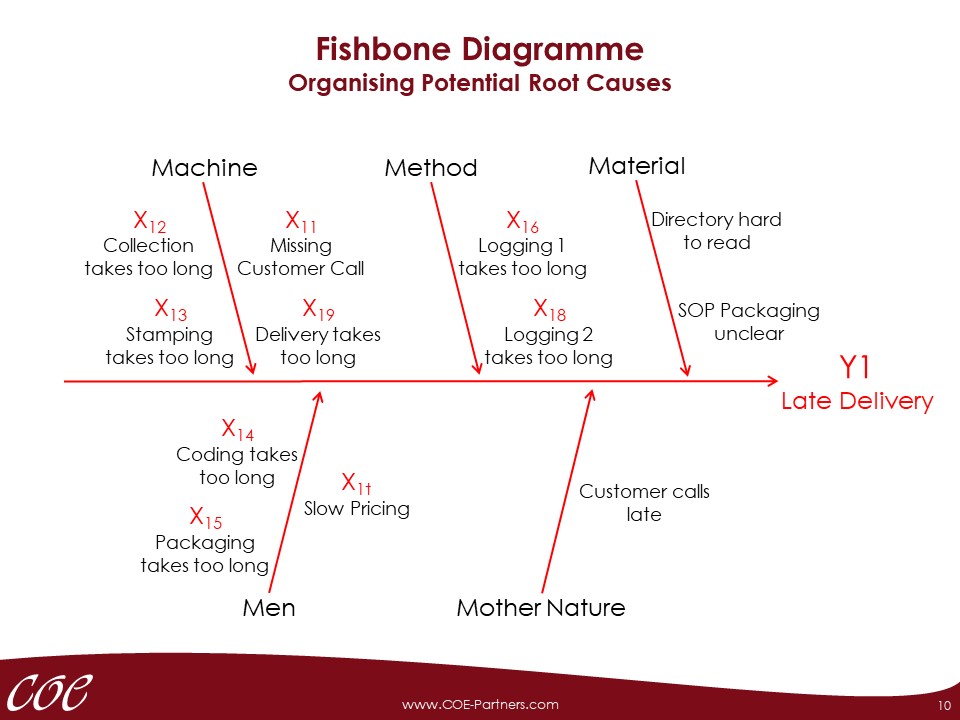
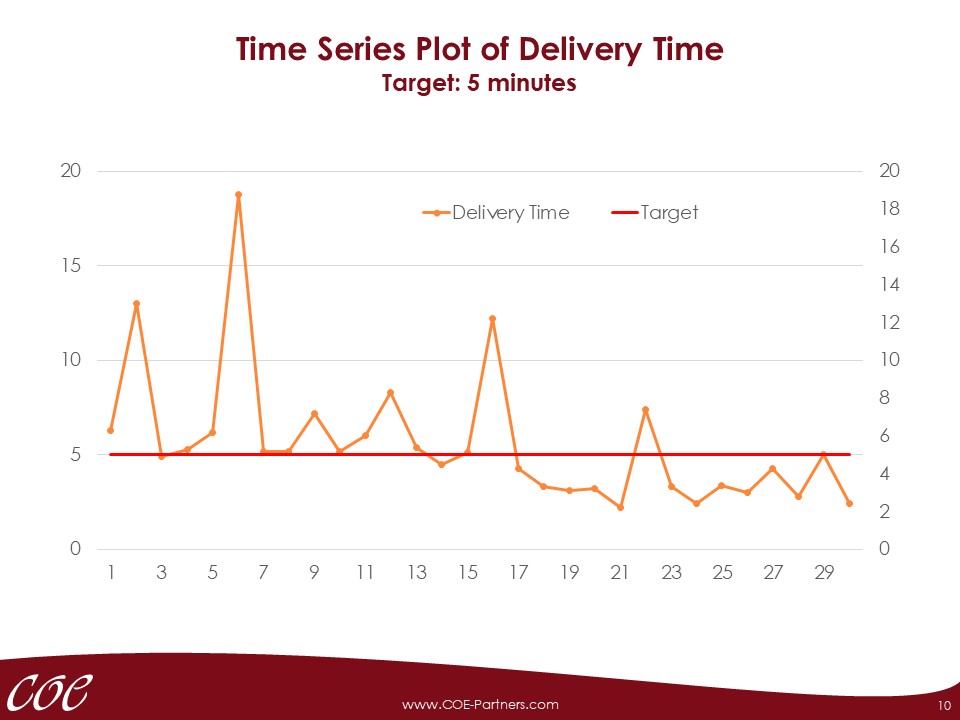
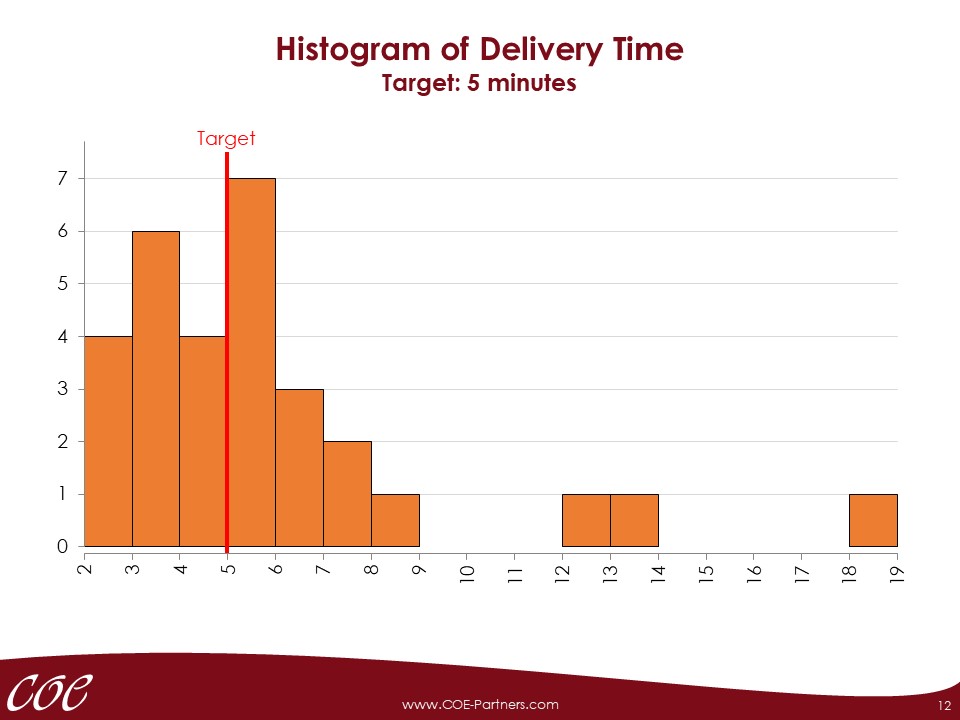
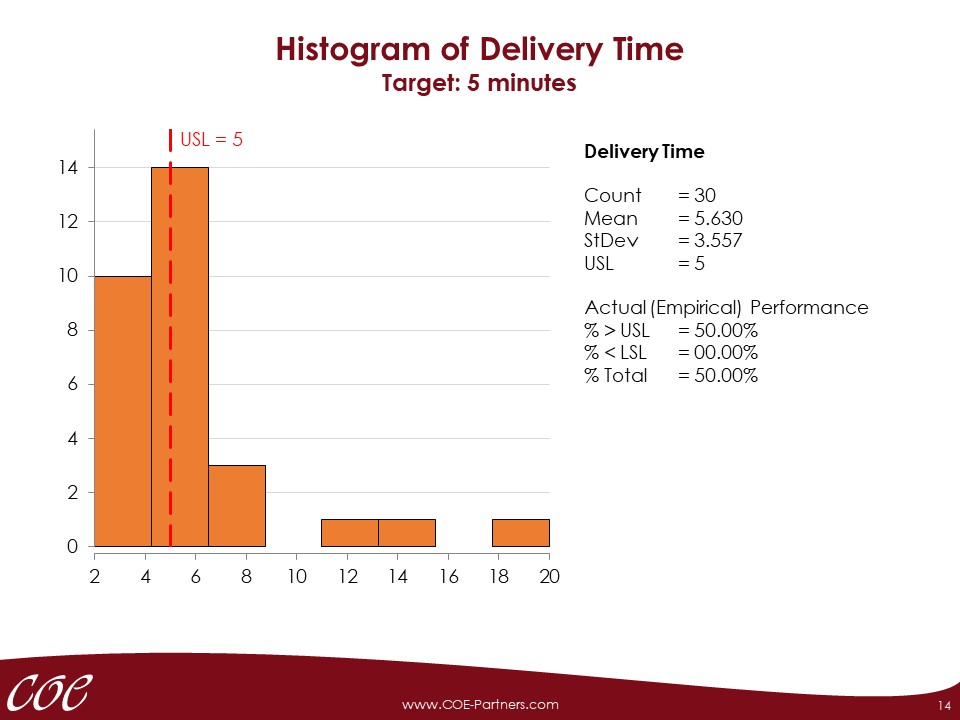
Before data for outcome variable (Y) and potential causes (Xs) are collected, the corresponding measurement systems have to be analysed. Measurement systems may cause various errors that can make the analysis of the process variation more difficult or impossible.
The goal of this step is therefore to analyse the variation resulting from measurement systems and to eliminate or to minimise it in order to ensure the usefulness of the data to be collected. The methods for measurement system analysis are tailored to the respective data types – continuous data and attribute data. Continuous data are quantitative, measurable, variable data, for instance, dimensions, time, weight. Attribute data are qualitative, discrete, countable data as number of errors, number of features. Attribute data with large frequency may be treated as continuous data.
Measurement systems must ensure accuracy, repeatability, reproducibility and stability of the measurement results.
Accuracy means the ability of a measurement system to accurately reflect the actual value. For example, when examining a customer loan request, ignoring missing information would be an inaccuracy that could have a negative impact on the downstream process.
Repeatability is the ability of a person to be able to repeat a score for the same object under the same conditions. For example, the declining attention of someone assessing loan applications towards the end of the working day may result in an inaccuracy that would not have happened in the morning.
Reproducibility refers to the ability to conduct an assessment by different persons and/or under different conditions with exactly the same result. For example, it would be a problem for the downstream process if the outcome of a credit risk analysis were dependent on the person examining the document, which means, if the same request were accepted by one person but rejected by another.
Stability identifies the ability of the measurement system to provide the same results long-term and not to be subjected to depreciation over time.
Accuracy Correction (Calibration) and Stability Analysis are methods that are beyond the scope of this page.
The method for verifying repeatability and reproducibility is also called Gage R & R (Gauge Repeatability and Reproducibility). This Gage R & R basically uses different procedures for different data types, continuous, i.e. variable and discrete, i.e. attribute data. Both methods of analysis examine the entire system including the measurement system, the sample, the tester and the environment.
For the measurement system analysis for attribute, i.e. discrete data, better be at least 20 – 30 typical units from the process are selected in such a way that approximately half are error-free and the other half are equipped with typical errors. This selection is made by a person familiar with the quality features, the so-called master.
Then, the units are presented to persons who are normally in charge of assessing this kind of units, without letting them know the assessment result by the master. A deviation of the evaluation by the examiner compared to that of the master results in reproducibility errors.
If the repeated examination of the same units by the same examiner under the same conditions leads to a deviation, a repeatability problem exists.
Repeated testing should be performed blindly. That is, the person assessing the units must not know the result of their previous evaluation of the same unit. In practice, this is not always easy to ensure. On the other hand, similar units can be used which have the same error in order to test the repeatability of the results.
The goal for both repeatability and reproducibility is 100%. Any deviation thereof means either allowing defective units to be passed to downstream process steps or holding back proper units. If these requirements are met, data collection can start immediately. In all other cases, the measurement system must be verified for the reasons for poor repeatability or reproducibility and corrective measures must be taken.
If there are obvious differences between repeatability characteristics for different persons, training measures may be adequate to improve the quality of the measurement system for single persons. If the measurements of all persons have a repeatability problem, the measurement system, that is, the combination of method, person, measuring means, measuring device and environmental conditions, should be questioned.
In the event of a reproducibility problem, the difference between the subject and the master shall be analysed and eliminated. Causes of this problem are to be found in inadequate instruction or inadequate training for the person concerned. If many assessing persons cannot be in agreement with the master, it is necessary to check whether the requirements for a unit for achieving ‘error-free’ assessment are precisely and comprehensively specified in test instructions.
This procedure is to be repeated until the measurement system capability meets the requirements.
This step has the following deliverables: